
Anonymizing patient information is crucial for privacy protection. Due to data sharing initiatives across research institutes and research projects, anonymization has become an important step in clinical research. When research studies that require expensive diagnostic resources such as fMRI, genetic testing, research organizations come together to share data for secondary analysis. Regulatory bodies such as the US Food and Drug Administration, Health Canada and EMA encourage data sharing initiatives.
Although there are several factors that contribute to decisions around what and how to anonymize patient information, regulatory requirements continue to be one of the most important factors. Depending on the regulatory requirements, disclosures and submissions have their own unique nuances. As such, the transformation approaches used in one submission may not be applicable to others, and a different approach may be needed.
Since 2019, Health Canada strongly encourages employing quantitative risk modeling methodologies. The European Medicine Agency too has suggested similar guidelines. These guidelines are reinforced by not only Policy 0070 but also with Clinical Trials Regulation (Regulation (EU) No 536/2014). In particular, pseudonymization of identifiers as opposed to outright suppression or redaction to preserve data utility. When sample sizes are small i.e. less than twenty patients, quantitative risk assessments will often yield the decision to outright suppress many of the identifiers. But the quantitative modeling process can help by generating transformation options for each identifier and provide the supporting evidence and rationale for the anonymization approach taken.
A fundamental problem in privacy-preserving data disclosures is how to make the right tradeoff between protecting patient privacy and data utility. Broadly speaking, patient privacy and data utility may have an inverse relationship. Researchers have observed that even for modest privacy gains complete destruction of the data utility may be needed. Another possible unintended consequence is that excessive protection of privacy, using techniques such as suppression (or removing data), can give misleading results and that could pose a public health risk.
These challenges can be tackled with the help of machine learning technology. Let’s elaborate using Figure 1.
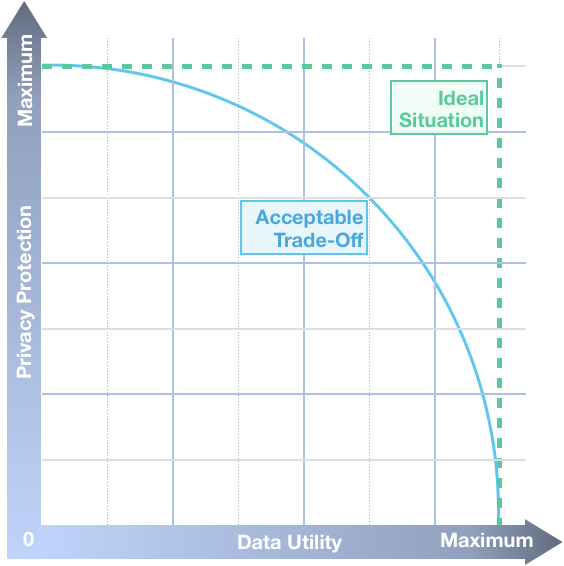
Figure 1. Finding an Acceptable trade-off
In Figure 1, data utility is represented on the x-axis and privacy protection is represented on the y-axis. For researchers, preserving data utility while maintaining patient privacy is the ideal situation. But often the ‘ideal situation’ of maximum patient privacy protection and maximum data utility may be impossible to achieve as it is ill-defined. Researchers try to focus on finding an acceptable ‘trade-off’ or the sweet spot where adequate data is retained without compromising patient privacy.
With the help of statistical modeling, instead of an ideal case scenario, an acceptable trade-off may be computed. This process can sometimes become iterative depending on how much data is lost in each round of quantitative modeling. Therefore, anonymization approaches must counterbalance the level of anonymization with the level of information loss. Typically, this will entail anonymizing certain identifiers with greater levels of anonymization than others, i.e. a tradeoff is made between levels of anonymization across identifiers to maximize the data utility and minimize the loss of information.
At Real Life Sciences (RLS), we have developed the industry leading purpose-built anonymization platform RLS Protect. RLS team of data anonymization experts collaborates with clients to determine the balance between the risk of re-identification and data utility. We welcome any and all queries related to your clinical trial transparency efforts
