
As data sharing becomes the new norm, protecting patient privacy and confidentiality has new challenges. Earlier in clinical trial datasets, redactions or blocking out sensitive information was a common practice. However, it made secondary analysis almost impossible. Regulatory authorities such as Health Canada have issued new guidelines for de-identifying data. These guidelines ensure patient privacy is protected and yet sufficient data is shared for derivative research projects.
While de-identifying data, sponsors and clinical research organizations are expected to comply with re-identification risk thresholds. Here we discuss how sources of the risk of re-identification influence quantitative thresholds of de-identification.
Patient re-identification risk can increase due to various sources. One of the common sources that increase the risk is cell size. Cell size refers to “the number of patients with the same indirectly-identifying variable values”. Fewer observations (frequencies less than 5 or 6) are often considered as a high risk for re-identification of patients and hence is unacceptable. In smaller datasets, these risks are evident. Some research centers may even require suppression of these variables. In a large dataset where frequencies are higher, there still may be a potential risk of re-identification. The risk of re-identification increases with the uniqueness of the record.
Another factor that creates risk is the visibility of the dataset. If a research dataset is public, then an adversary may launch a ‘demonstration attack’ to gain more publicity. This requires the maximum possible deidentification. For non-public datasets, how partial health information can be linked with public datasets such as credit data, consumer records, etc. can influence the de-identification process. An adversary may link these two unrelated datasets and re-identify patients. Sponsors and CROs are often aware of sensitive variables in the dataset and may have taken the necessary steps to de-identify these variables. But an adversary may link an adequate number of least sensitive variables to re-identify patients.
Lastly, personal knowledge or press accounts of an event (e.g., suicide attempt by a celebrity) may enable an adversary to search for that high-profile subject in a research dataset. Although press accounts or personal knowledge cannot be controlled, sponsors and CROs can make patient re-identification difficult by de-identifying data at appropriate statistical risk thresholds.
Statistical computation of risk thresholds can help determine low, medium, or high levels of risks. In 2016, the Information and Privacy Commissioner of Ontario (IPCO) issued de-identification guidelines for structured data that guide determining an acceptable re-identification risk threshold. If the re-identification risk of data is higher or the threshold for re-identification risk was liberal then a greater amount of de-identification will become necessary to protect patient identity. The risk threshold is defined as “the minimum amount of de-identification that must be applied to a data set in order for it to be considered de-identified”. Risk thresholds may vary by the circumstances of data sharing. For instance, if data is shared in a controlled environment under a signed data sharing agreement, the risk threshold required on the data may be lower, as the investigator using it is legally agreeing not to re-identify individuals. Here we consider risk thresholds as suggested by regulatory authorities.
Based on the cell sizes, the IPCO has also provided guidelines for risk re-identification threshold.
| Invasion of Privacy | Re-identification Risk Threshold | Cell Size Equivalent |
| Low | 0.1 | 10 |
| Medium | 0.075 | 15 |
| High | 0.05 | 20 |
Table 1. The IPCO guideline for re-identification risk threshold.
Various researchers have proposed threshold values ranging from 0.3 to 0.01. However, Health Canada currently recommends a threshold of 0.09 or a 9% risk of patient re-identification. A 9% risk means a target cell size is 11 patients. The EMA Policy 0070 External Guidance also recommends 0.09 as a threshold but its implementation is not yet widespread. These quantitative thresholds make sure that data utility is preserved. They also make the de-identification process less subjective and precise which allows artificial intelligence technology tools to do the task.
Ensuring risk thresholds are met can be a complicated task. Fortunately, since risk thresholds are expressed quantitatively, data science experts can help with the task. As part of the data utility considerations, we actively collaborate to ensure key variables for the disclosure are best maintained. Additionally, if the clinical trial is conducted within a small and sensitive population, it requires special consideration and our experts can help with the risk thresholds. Our team of specialists can help sponsors to de-identify data at risk thresholds determined by the applicable regulatory authority. Real Life Sciences has developed tools for de-identifying the data using Natural Language Processing technology. RLS Protect platform makes the process of de-identification at a specific threshold easier and more accurate. Real Life Sciences offers tailor-made solutions for data de-identification. Contact Real Life Sciences.
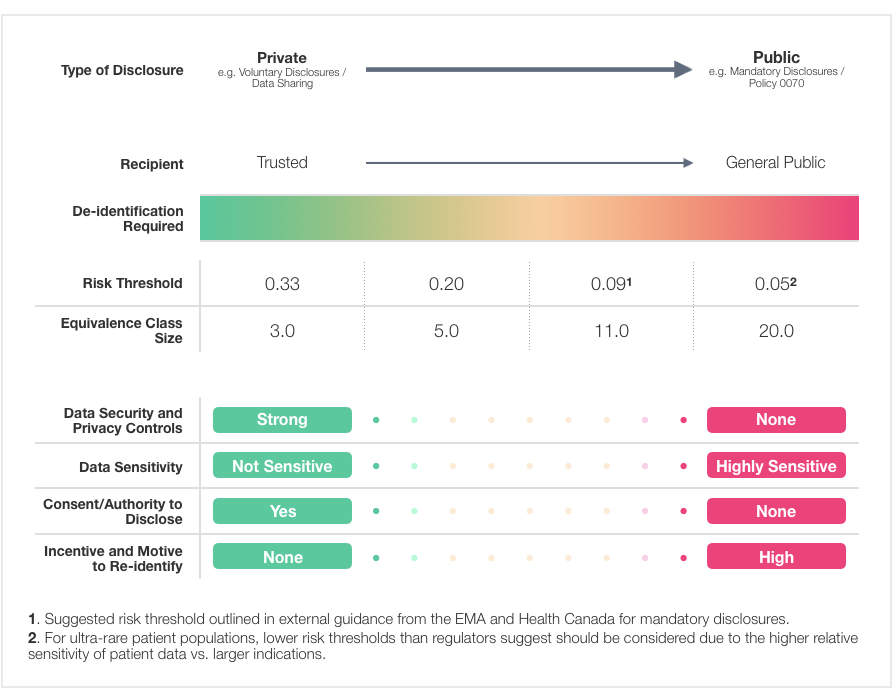
Risk Thresholds and Equivalence Class Sizes Based on Types of Disclosure